Denoising-based diffusion models have attained impressive
image synthesis; however, their applications on videos
can lead to unaffordable computational costs due to the per-frame
denoising operations. In pursuit of efffcient video generation, we
present a Diffusion Reuse MOtion (Dr. Mo) network to accelerate
the video-based denoising process. Our crucial observation is that
the latent representations in early denoising steps between adjacent
video frames exhibit high consistencies with motion clues.
Inspired by the discovery, we propose to accelerate the video
denoising process by incorporating lightweight, learnable motion
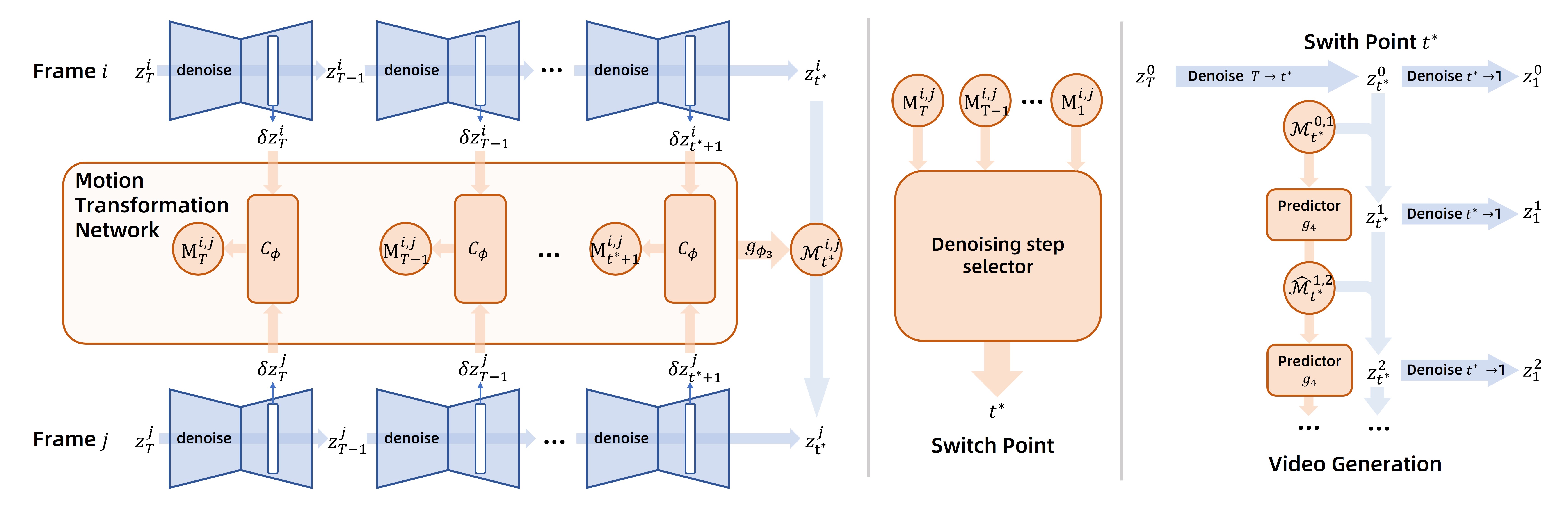
features. Speciffcally, Dr. Mo will only compute all denoising steps
for base frames. For a non-based frame, Dr. Mo will propagate
the pre-computed based latents of a particular step with interframe
motions to obtain a fast estimation of its coarse-grained
latent representation, from which the denoising will continue to
obtain more sensitive and ffne-grained representations. On top
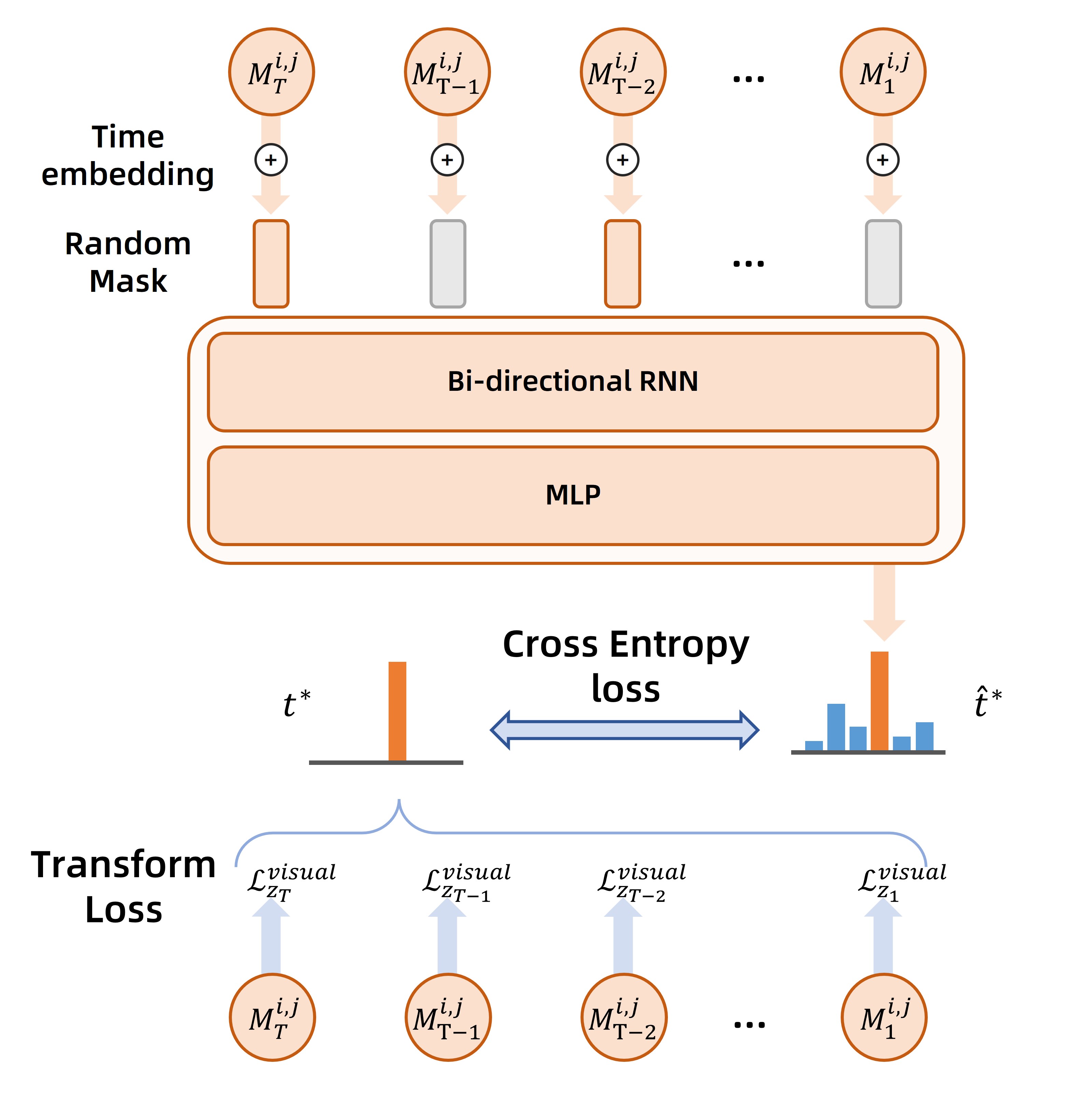
of this, Dr. Mo employs a meta-network named Denoising Step
Selector (DSS) to dynamically determine the step to perform
motion-based propagations for each frame, which can be viewed
as a tradeoff between quality and efffciency. Extensive evaluations
on video generation and editing tasks indicate that Dr. Mo
delivers widely applicable acceleration for diffusion-based video
generations while effectively retaining the visual quality and
style.